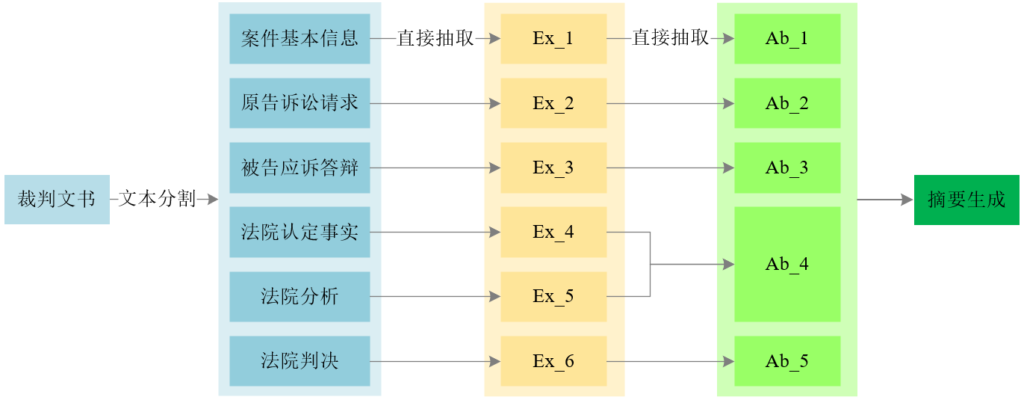
民事一审判决书自动摘要Demo介绍, 科研成果 判决书作为司法判决的载体对研究我国法律实践发展、促进法律实体正义与程序正义、提高司法效率具有重要意义。但由于判决书内容往往较长、非结构化、当事人关系复杂、事件类型多样等因素,往往难以高效快速的提取判决书中的要点。 基于此,本文针对民事一审判决书提出“分割+抽取+生成”摘要自动生成模型。 一键体验 Demo 介绍 专业 高效 准确 用户可以输入整个判决书并通过程序对其自动进行分割,也可以手动将判决书分割后输入;通过“抽取式摘要”按钮,获得抽取式摘要;通过“生成式摘要”按钮,获得生成式摘要。 三 个 阶 段 判决书文本分割阶段:基于正则规则提取出判决书中的重要信息; 抽取式摘要阶段:基于NEZHA预训练模型抽取摘要; 生成式摘要阶段:借鉴Unilm在生成式任务上的机制,仍然基于NEZHA预训练模型进行生成式摘要。 模 型 特 点 基于判决书自身特点,统计正则规则对文本进行分割,降低文本长度的同时,帮助模型更好地学习各部分内容的特点;抽取、生成阶段统一采用NEZHA预训练模型,该模型由华为提出,在中文NLP任务上具有良好表现;相比于采用同样数据集(http://cail.cipsc.org.cn:2020/)的最好结果提升近16%。 感谢南开大学网络空间安全学院2017级信息安全、法学双学位班王冲同学的工作对本网站建设的支持。